Learning SQL about Redundant Indexes Server
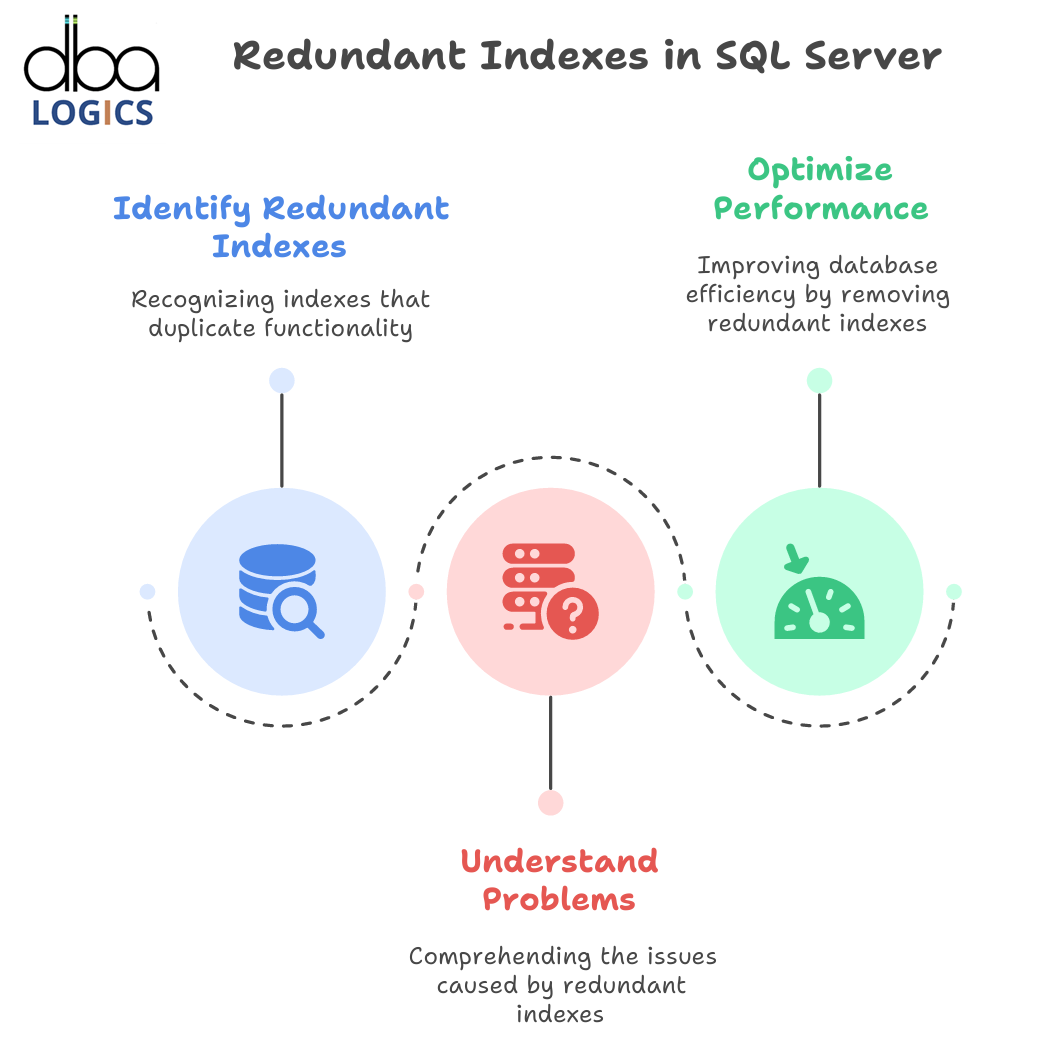
In this briefly highlights what redundant indexes in SQL server are all about. what they are, why they are bad, how one can know about them, and why it is necessary to know about them. deleting them to provide better performance of the databases.
What are redundant Indexes?

Overlapping index is a redundant index together with the purpose inside an SQL Server database. It happens when there are two or more than two indexes on the same table by having the columns comprising the identical columns arranged in an identical or equivalent sequence. SQL Server query optimizer may select between either of the two indexes to fulfill a query. Even though indexes do tend to enhance read performance, holding unnecessary indexes may lead to inefficiencies.
Storing redundant indexes in SQL server is disadvantageous to a database in several aspects:

- They occupy additional storage spaces. Both indexes consume space. Precious database size is created through unnecessary indexes.
- They demoralize writes. Whenever we change data (insert, modify, or delete), we have to redone all the indexes in the tables in SQL server. Additional indexes increase the price of these write processes and slow them.
- They contribute to the index upkeep efforts. tasks such as index rebuild and reorganization take a longer duration when indexes are many to deal with.
- They increase the load of the query optimizer. This tool considers various indexes, some of which are unnecessary, which makes it take longer time in determining the most suitable method of pursuing a query.
Example:
Suppose you have these two indexes on a table:
- -- Index 1
- CREATE NONCLUSTERED INDEX IX_Employee_Department
- ON Employees (Department);
- -- Index 2 (Redundant)
- CREATE NONCLUSTERED INDEX IX_Employee_Department_Location
- ON Employees (Department, Location);
The combination of Department and Location can be filtered with index 2 (IX_Employee_Department_Location ). It also can be filtered using only by Department as the first column is Department. Index 1 (IX_Employee_Department) is unnecessary hence it is redundant.
The SQL Server does not show a warning to indexes that are redundant.

You can come across them included in viewing of the index definition and the usage statistics. In the next steps, do the following:
- Study definitions of indices. Take advantage of the
sys.indexes,sys.indexe_columnsviews. Make sure of the columns which are in the index and that they are in order. - Determine the possibility of overlap. Compare indexes with identical columns, or with partially matching columns. Index (A, B) is able to support only the queries that filter based on A, and index (B, A) is not able to support efficiently those queries that filter based only on A.
- Review usage statistics of checks. Check the usage of each index using the sys.dm_db_index_usage_stats dynamic management view to view the frequency of each of the indexes. Indexes, which have low usage are the most likely to become redundant.
In order to identify the unused indexes, query all non-clustered indexes, with a listing of the columns and the order of that column:
- SELECT
- OBJECT_NAME(i.object_id)AS TableName,
- i.name AS IndexName,
- COL_NAME(ic.object_id,ic.column_id)AS ColumnName,
- ic.key_ordinal AS ColumnOrder
- FROM sys.indexes AS i
- INNER JOIN sys.index_columns AS ic
- ON i.object_id=ic.object_id AND i.index_id = ic.index_id
- WHERE
- i.type_desc='NONCLUSTERED'
- ORDER BY TableName, IndexName, ColumnOrder

This query attended to the listing of the non-clustered indexes including their columns as well as the employee names. By looking at the output, it is possible to know indexes that share in common the sets of columns. Besides, to inspect the usage of indexes, you can use the next query:
- SELECT
- OBJECT_NAME(ius.object_id) AS TableName,
- i.name AS IndexName,
- ius.user_seeks,
- ius.user_scans,
- ius.user_lookups,
- ius.user_updates
- FROM
- sys.dm_db_index_usage_stats AS ius
- INNER JOIN
- sys.indexes AS i
- ON
- ius.object_id = i.object_id AND ius.index_id = i.index_id
- WHERE
- OBJECTPROPERTY(ius.object_id, 'IsUserTable') = 1
- ORDER BY
- ius.user_seeks + ius.user_scans + ius.user_lookups DESC

Dropping Duplicate Indexes
- Test non-production. Select an environment which reflects as much as possible the production.
- Monitor query performance. Once after dropping an index, monitor the performance of queries that may utilize the index. Take the query execution plans by using SQL Server Profiler or Extended Events, and then query for any performance regressions.
- Think of a progressive approach. When you are not sure whether you want an index, then you should disable it rather than dropping it. Removal of an index disallows the query optimizer to use it, but retains the index definition and the data. After some time, you can ditch the index in case you do not observe any adverse impacts.
- Test non-production. Select an environment which reflects as much as possible the production.
- Monitor query performance. Once after dropping an index, monitor the performance of queries that may utilize the index. Take the query execution plans by using SQL Server Profiler or Extended Events, and then query for any performance regressions.
- Think of a progressive approach. When you are not sure whether you want an index, then you should disable it rather than dropping it. Removal of an index disallows the query optimizer to use it, but retains the index definition and the data. After some time, you can ditch the index in case you do not observe any adverse impacts.






Post Comment
Your email address will not be published. Required fields are marked *